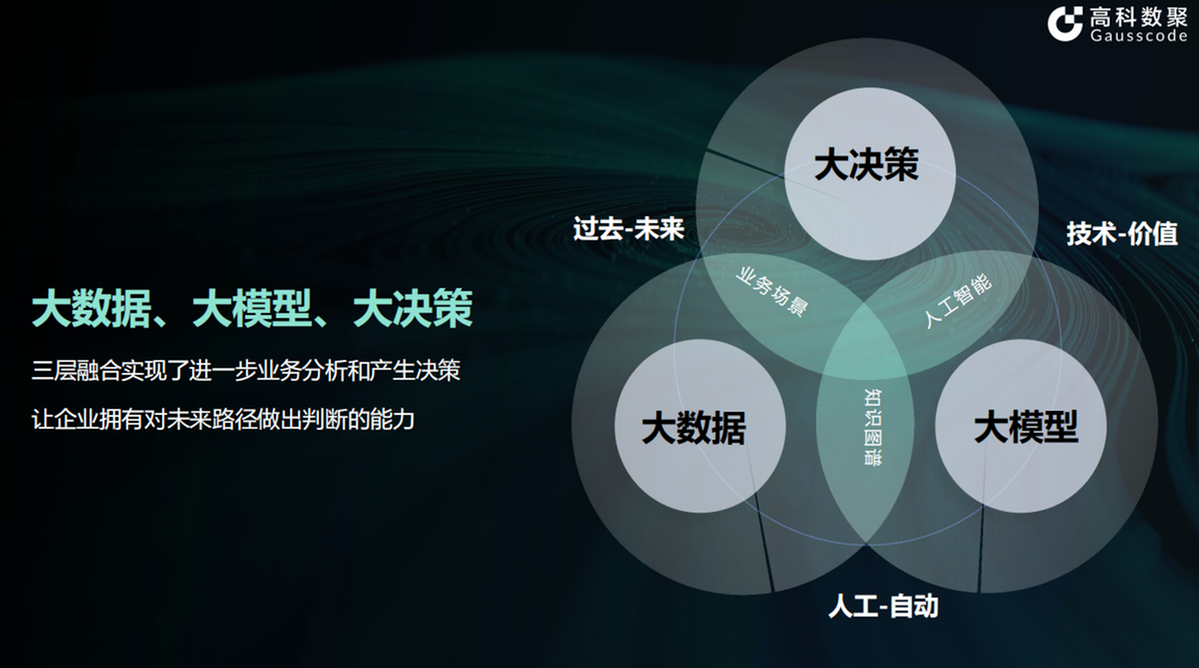
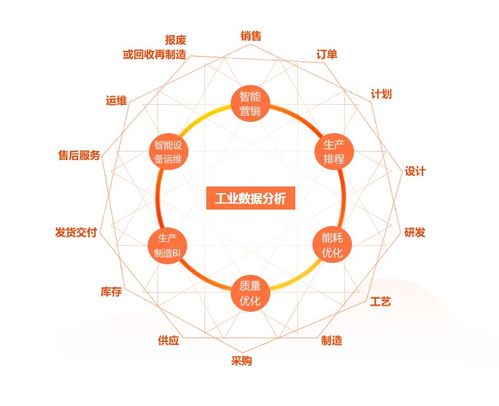
在信息爆炸的今天,大數(shù)據(jù)已成為驅動社會進步和商業(yè)創(chuàng)新的核心動力。海量、多樣、快速生成的數(shù)據(jù)本身并不直接產生價值,關鍵在于如何從中高效、精準地提取所需信息。這正是高級搜索技術在大數(shù)據(jù)時代扮演決定性角色的舞臺。
一、大數(shù)據(jù)環(huán)境下的搜索范式轉變
傳統(tǒng)的關鍵詞搜索,在面對TB甚至PB級別的非結構化或半結構化數(shù)據(jù)(如社交媒體文本、傳感器日志、圖像視頻)時,往往力不從心,返回結果冗雜且相關性低。高級搜索技術實現(xiàn)了從“簡單匹配”到“智能發(fā)現(xiàn)”的范式躍遷。它融合了自然語言處理(NLP)、機器學習、語義理解、知識圖譜和分布式計算等前沿技術,旨在理解用戶的深層意圖和上下文,而不僅僅是字面查詢。
例如,一個分析師查詢“上個季度華東地區(qū)新能源汽車的銷售波動原因”,高級搜索系統(tǒng)能夠理解“上個季度”的時間范圍、“華東地區(qū)”的地理位置、“新能源汽車”的產品類別以及“銷售波動原因”的分析意圖。它隨后會關聯(lián)內部銷售數(shù)據(jù)庫、外部市場報告、行業(yè)新聞甚至社交媒體輿情,進行多源異構數(shù)據(jù)的交叉分析與挖掘,最終提供結構化的洞察摘要和相關證據(jù)鏈,而非僅僅是一堆包含這些關鍵詞的文檔列表。
二、核心技術與應用場景
- 語義搜索與知識圖譜:通過構建包含實體、屬性及關系的知識圖譜,系統(tǒng)能夠理解概念間的邏輯關聯(lián)。搜索“蘋果”時,能根據(jù)上下文區(qū)分是水果、公司還是手機品牌,并關聯(lián)其CEO、最新財報、供應鏈新聞等,實現(xiàn)深度知識探索。
- 向量化搜索與嵌入模型:利用深度學習模型(如BERT、GPT系列)將文本、圖像乃至語音轉換為高維向量(嵌入)。搜索時,直接計算查詢與數(shù)據(jù)向量之間的相似度,能夠發(fā)現(xiàn)語義相似但措辭不同的內容,極大提升了召回率與相關性。這在推薦系統(tǒng)、專利檢索和內容去重中效果顯著。
- 聯(lián)邦搜索與跨源聚合:企業(yè)數(shù)據(jù)常散落在數(shù)據(jù)湖、數(shù)據(jù)倉庫、云存儲及各類SaaS應用中。高級搜索平臺能通過連接器和API,在不移動原始數(shù)據(jù)的前提下(符合數(shù)據(jù)治理要求),實現(xiàn)跨系統(tǒng)、跨地域的統(tǒng)一索引與查詢,提供一站式信息視圖。
- 實時搜索與流處理:結合Apache Kafka、Flink等流處理框架,高級搜索可以對數(shù)據(jù)流(如物聯(lián)網傳感器數(shù)據(jù)、金融交易流、線上點擊流)進行即時索引與查詢,滿足監(jiān)控、欺詐檢測、個性化推薦等對時效性要求極高的場景。
三、面臨的挑戰(zhàn)與未來方向
盡管前景廣闊,高級搜索在大數(shù)據(jù)中的應用仍面臨諸多挑戰(zhàn):
- 計算復雜度與成本:對海量數(shù)據(jù)進行實時向量化、索引更新和相似度計算,需要巨大的計算資源和優(yōu)化的分布式算法。
- 數(shù)據(jù)質量與偏見:搜索結果的公正性和準確性高度依賴于訓練數(shù)據(jù)和知識圖譜的質量。“垃圾進,垃圾出”,數(shù)據(jù)中的偏見會被搜索系統(tǒng)放大。
- 隱私與安全:跨源搜索和數(shù)據(jù)聚合必須嚴格遵守GDPR等數(shù)據(jù)隱私法規(guī),如何在保護用戶隱私的同時實現(xiàn)有效搜索,是技術也是合規(guī)的難題。
- 查詢意圖的模糊性:準確捕捉用戶復雜、動態(tài)變化的意圖,尤其是面向專業(yè)領域的探索性分析,仍需人機交互與反饋機制的持續(xù)優(yōu)化。
高級搜索將更加趨向智能化、個性化和場景化。與生成式AI(AIGC)的結合將是下一個爆發(fā)點——搜索系統(tǒng)不僅能“查找”信息,更能直接“生成”整合了多源數(shù)據(jù)的報告、摘要或答案。搜索將更深地嵌入到具體業(yè)務流程中,成為決策智能的天然接口。
###
大數(shù)據(jù)是蘊藏價值的礦山,而高級搜索則是高效、智能的采礦與精煉系統(tǒng)。它正從一項輔助工具演變?yōu)槠髽I(yè)數(shù)據(jù)驅動能力的核心基礎設施。只有持續(xù)投入并攻克相關技術與管理挑戰(zhàn),組織才能真正將數(shù)據(jù)的規(guī)模優(yōu)勢轉化為決策的精準優(yōu)勢與創(chuàng)新的速度優(yōu)勢,在信息時代保持領先。